In Implementing a Drive-Based Controller with Memory, we developed a simple, unlearned controller that sets goals based on drive classification over remembered sensory inputs. We also added a local map to this controller that allowed it to deviate from its goals slightly to avoid threats and approach opportunities.
This agent has a fundamental flaw, though, in that it cannot “see” the rewards it is getting or not getting. The classifier is trained to classify the tree embeddings, but the “smell” sensor does not naturally localize since it is a proximity sensor. Without a way to move from proximity to exact location, the agent can only find food by getting lucky.
We could fix this by introducing a directional “vision” sensor with a more distinct range. However, it would be interesting to know what we can do with the imprecise smell sensor, which does contain directional information that could be extracted when combined with the knowledge of where rewards were obtained.
In this notebook, we will use reinforcement learning to control the local deviations from target so that the agent can exploit better.
Capturing Rewards¶
In order to do any reinforcement learning, we have to first alter our agent to record the results of when it has eaten fruit and pass this to the model. This requires updating AgentModel.get_action to take a reward parameter.
import torch
class Agent:
# ...
def step(self, world: 'TreeWorld'):
distance, embedding, tree = self.sensor.sense(world, self.location, self.heading)
reward = 0.0
if tree is not None and distance < self.eat_distance:
# print(f"Eating fruit from tree {tree.name} with fruit amount {num_fruit}")
self.fruit_eaten += 1
reward = 1.0
if tree.is_poisonous:
self.poisonous_fruit_eaten += 1
reward = -1.0
# NOTE: this requires the agent to face the tree when eating fruit
self.eat_fruit(1, tree.is_poisonous)
tree.harvest_fruit()
position_delta, self.heading = self.model.get_action(
distance,
embedding,
self.heading,
self.health / self.max_health,
agent_location=self.location,
obj_location=tree.location if tree is not None else None,
reward=reward
)
if position_delta is None or torch.norm(position_delta) < 1e-8:
self.rest()
else:
self.move(position_delta)
# ...class AgentModel:
def get_action(self, distance: float, embedding: torch.Tensor, heading: torch.Tensor, health: float,
agent_location: torch.Tensor=None, obj_location: torch.Tensor=None, reward: float=0.0):
# ...
passImplementing a REINFORCE-style Policy Gradient¶
Policy gradient methods use a neural network policy to decide on actions. That is, they sample a distribution
In our case, we already have a heading , and we are looking for a deviation so that we can output
where is the left-pointing orthonormal vector from the heading . We also do not need to condition the decision on past actions or past states. Thus we want our policy to sample
where is just the local map developed towards the end of Implementing a Drive-Based Controller with Memory and provides a view into the last decision for consistency.
As is typical, the policy is learned by optimizing the discounted sum of rewards with discount , using the log-trick
where is the advantage against a baseline that is independent of (and hence ),
Methods such as PPO and GRPO craft this baseline carefully, but in our case, we will be starting with online policy learning against a baseline from the simple drive-based controller without RL.
Every 100 steps we will update our policy using based on rewards achieved from the past 100 steps. We will alternate between using the policy to guide the agent (on-policy) and using the non-learned drive-based controller (off-policy) every other simulation. The baseline will be updated only when the non-learned policy is used. We will only train when the total rewards is non-zero.
For reference, we will be using build_forward_local_map with return_raw_drives=True to create our input
import math
from tree_world.states import DriveManager, Location
from tree_world.models.memory import SpatialMemory
def build_forward_local_map(
memory: SpatialMemory,
location: Location,
heading: torch.Tensor,
drive_manager: DriveManager,
num_grid_points: int=10,
grid_size: float=10.0,
match_threshold: float=25.0,
return_raw_drives: bool=False,
):
axis_points = torch.arange(num_grid_points, dtype=heading.dtype, device=heading.device)
axis_grid = torch.cartesian_prod(axis_points, axis_points)
# we want to get the vector to the diagonal of the grid, which is y=x
rotation_matrix = math.sqrt(0.5) * torch.tensor([
[1, 1],
[-1, 1],
], dtype=heading.dtype, device=heading.device)
grid_points_relative = (axis_grid @ rotation_matrix.T) * grid_size
heading_normalized = heading / torch.norm(heading)
heading_orthogonal = torch.tensor([-heading_normalized[1].item(), heading_normalized[0].item()],
dtype=heading.dtype, device=heading.device)[None, :]
grid_points_absolute = location.location[None, None, :] + (
grid_points_relative[..., 0, None] * heading_normalized + grid_points_relative[..., 1, None] * heading_orthogonal
)[None, ...]
grid_locations_sd = torch.ones_like(grid_points_absolute) * grid_size / 2
memory_values = memory.read(grid_points_absolute, grid_locations_sd, match_threshold=match_threshold).squeeze(0)
grid_valence = drive_manager.assess_valence(memory_values, return_raw_drives=return_raw_drives)
deviations = grid_points_relative[..., 1]
return grid_points_absolute, grid_valence, deviations, heading_orthogonalWe will use the grid_valence, which is a tensor of shape (num_grid_points, num_grid_points, 3), as our network input , and heading_orthogonal as the orthogonal unit vector .
Here is a simple MLP for the policy network:
from typing import Optional
class LocalMapPolicy(torch.nn.Module):
def __init__(self, drive_field_dim: int, hidden_dim: int=128, scale: float=25.0):
super().__init__()
self.scale = scale
self.fc1 = torch.nn.Linear(drive_field_dim + 1, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, hidden_dim)
self.fc3 = torch.nn.Linear(hidden_dim, 2)
def forward(self, x: torch.Tensor, last_coefficient: torch.Tensor, output: Optional[torch.Tensor]=None) -> torch.Tensor:
x = torch.relu(self.fc1(torch.cat([x, last_coefficient], dim=1)))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
mean_output = x[:, 0] * self.scale
std_output = torch.nn.functional.softplus(x[:, 1])
if output is None:
output = mean_output + std_output * torch.randn_like(mean_output)
log_prob = -torch.log(std_output) - 0.5 * ((output - mean_output) / std_output) ** 2 - 0.5 * math.log(2 * math.pi)
return output, log_prob.mean()The output is scaled by a factor that should be equal to grid_size num_grid_points so that the neural network output can be scaled to the range from the raw weight output of .
We’ll also put a small penalty on switching the sign of the coefficient, to encourage “differentiable” trajectories.
Finally, we can extend tree_world.drive_agents.DriveBasedAgentWithMemory to implement the policy-backed controller.
from tree_world.drive_agents import DriveBasedAgentWithMemory, apply_deviation
from tree_world.simulation import TreeWorld
from typing import Optional
class DriveBasedAgentWithLocalPolicy(DriveBasedAgentWithMemory):
deviation_strength: float = 5.0
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.grid_size = 5.0
self.num_grid_points = 5
drive_field_dim = self.num_grid_points * self.num_grid_points * 3
self.policy = LocalMapPolicy(drive_field_dim, scale=self.grid_size * self.num_grid_points / 4)
self.optimizer = torch.optim.AdamW(self.policy.parameters(), lr=1e-3)
self.total_rewards = 0.0
self.total_rewards_baseline = 0.0
self.total_rewards_baseline_decay = 0.9
self.total_log_probs = 0.0
self.use_policy = True
self.last_coefficient = 0.0
def reset(self):
super().reset()
self.total_rewards = 0.0
self.last_coefficient = 0.0
self.use_policy = not self.use_policy
# print the execution stack to see who is calling reset
if self.use_policy:
print(f"Using policy model")
else:
print(f"Using baseline model")
def update_rewards(self, reward: float):
self.total_rewards += reward
def heading_from_policy(self, heading: torch.Tensor, agent_location: Location, output: Optional[torch.Tensor]=None):
_, drive_field, _, heading_orthogonal = build_forward_local_map(
self.memory, agent_location, heading, self.drive_manager,
num_grid_points=self.num_grid_points, grid_size=self.grid_size,
match_threshold=25.0, return_raw_drives=True
)
drive_field = drive_field.view(1, -1)
last_coefficient = torch.tensor([[self.last_coefficient]], dtype=drive_field.dtype, device=drive_field.device)
coefficient, log_prob =self.policy(drive_field.detach(), last_coefficient, output)
self.total_log_probs = self.total_log_probs + log_prob
raw_heading = heading + coefficient.squeeze(0) * heading_orthogonal.squeeze(0)
heading_norm = torch.norm(heading)
return (heading_norm * raw_heading / torch.norm(raw_heading)).detach(), coefficient.squeeze(0)
def heading_from_deviation(self, heading: torch.Tensor, agent_location: Location):
return apply_deviation(
agent_location, heading, self.memory, self.drive_manager,
deviation_strength=self.deviation_strength,
num_grid_points=5, grid_size=5.0, match_threshold=25.0,
return_coefficient=True
).detach().squeeze()
def adjust_heading(self, heading: torch.Tensor, agent_location: Location):
if self.use_policy:
heading, coefficient = self.heading_from_policy(heading, agent_location)
self.last_coefficient = coefficient.item()
return heading
else:
output = self.heading_from_deviation(heading, agent_location)
return self.heading_from_policy(heading, agent_location, output)[0]
def train(self):
super().train()
if self.total_rewards == 0.0:
return
self.optimizer.zero_grad()
advantage = self.total_rewards - self.total_rewards_baseline
loss = -advantage * self.total_log_probs
loss.backward()
self.optimizer.step()
if not self.use_policy:
d = self.total_rewards_baseline_decay
self.total_rewards_baseline = self.total_rewards_baseline * d + self.total_rewards * (1.0 - d)
self.total_log_probs = 0.0
self.total_rewards = 0.0Testing the RL Policy¶
Our simulation will call train every 100 steps on any agent model that has a train method, meaning that our model will be trained online every 100 steps. We’ll want to run a few runs to track the policy.
from tree_world.simulation import TreeWorldConfig, TreeWorld, SimpleSensor
R = 50
D = 1024
S = 2 * R + 1
real_magnitude = 500.0
config = TreeWorldConfig()
config.embed_dim = D
config.max_memory_size = S**2
config.model_type = "DriveBasedAgentWithLocalPolicy"
sensor = SimpleSensor.from_config(config)
world = TreeWorld.random_from_config(config)Drive Embedding Classifier Loss (with fruit amount): 0.3053666055202484 MSE: 8.096726560324896e-06 Accuracy: 100.00%
def run_simulation(world: TreeWorld, steps: int=1000, record: bool=False):
world.randomize()
print(f"Running tree world for {steps} steps...")
world.run(steps, record=record)
print()
print("Tree world run complete.")
print(f"Agent health: {world.agent.health}")
print(f"Agent fruit eaten: {world.agent.fruit_eaten}")
print(f"Agent poisonous fruit eaten: {world.agent.poisonous_fruit_eaten}")
print(f"Agent total movement: {world.agent.total_movement}")
print(f"Agent final location: {torch.norm(world.agent.location).item()}")
for i in range(50):
run_simulation(world, steps = (i + 1) * 1000)Using baseline model
Running tree world for 1000 steps...
Tree world run complete.
Agent health: 799.98779296875
Agent fruit eaten: 32
Agent poisonous fruit eaten: 16
Agent total movement: 1000.0
Agent final location: 511.715087890625
Using policy model
Running tree world for 2000 steps...
Tree world run complete.
Agent health: 655.3789672851562
Agent fruit eaten: 19
Agent poisonous fruit eaten: 0
Agent total movement: 2000.0
Agent final location: 323.0830993652344
Using baseline model
Running tree world for 3000 steps...
Tree world run complete.
Agent health: 839.990234375
Agent fruit eaten: 55
Agent poisonous fruit eaten: 0
Agent total movement: 3000.0
Agent final location: 365.2728576660156
Using policy model
Running tree world for 4000 steps...
Tree world run complete.
Agent health: 299.951171875
Agent fruit eaten: 34
Agent poisonous fruit eaten: 15
Agent total movement: 4000.0
Agent final location: 128.1287078857422
Using baseline model
Running tree world for 5000 steps...
Tree world run complete.
Agent health: -0.03589621186256409
Agent fruit eaten: 15
Agent poisonous fruit eaten: 15
Agent total movement: 3125.0
Agent final location: 204.41065979003906
Using policy model
Running tree world for 6000 steps...
Tree world run complete.
Agent health: 674.9267578125
Agent fruit eaten: 43
Agent poisonous fruit eaten: 4
Agent total movement: 6000.0
Agent final location: 481.16546630859375
Using baseline model
Running tree world for 7000 steps...
Tree world run complete.
Agent health: 602.1757202148438
Agent fruit eaten: 125
Agent poisonous fruit eaten: 15
Agent total movement: 7000.0
Agent final location: 166.11886596679688
Using policy model
Running tree world for 8000 steps...
Tree world run complete.
Agent health: -19.012222290039062
Agent fruit eaten: 50
Agent poisonous fruit eaten: 29
Agent total movement: 3312.0
Agent final location: 99.50843048095703
Using baseline model
Running tree world for 9000 steps...
Tree world run complete.
Agent health: -0.1997298300266266
Agent fruit eaten: 35
Agent poisonous fruit eaten: 35
Agent total movement: 626.0
Agent final location: 474.69561767578125
Using policy model
Running tree world for 10000 steps...
Tree world run complete.
Agent health: -0.003253564238548279
Agent fruit eaten: 36
Agent poisonous fruit eaten: 36
Agent total movement: 500.0
Agent final location: 285.6163330078125
Using baseline model
Running tree world for 11000 steps...
Tree world run complete.
Agent health: -0.04569198191165924
Agent fruit eaten: 26
Agent poisonous fruit eaten: 12
Agent total movement: 5250.0
Agent final location: 136.88357543945312
Using policy model
Running tree world for 12000 steps...
Tree world run complete.
Agent health: -0.007545098662376404
Agent fruit eaten: 23
Agent poisonous fruit eaten: 23
Agent total movement: 2125.0
Agent final location: 500.71844482421875
Using baseline model
Running tree world for 13000 steps...
Tree world run complete.
Agent health: 579.7743530273438
Agent fruit eaten: 234
Agent poisonous fruit eaten: 69
Agent total movement: 13000.0
Agent final location: 323.87677001953125
Using policy model
Running tree world for 14000 steps...
Tree world run complete.
Agent health: -18.8597412109375
Agent fruit eaten: 106
Agent poisonous fruit eaten: 51
Agent total movement: 5594.0
Agent final location: 218.62242126464844
Using baseline model
Running tree world for 15000 steps...
Tree world run complete.
Agent health: -5.8734540939331055
Agent fruit eaten: 24
Agent poisonous fruit eaten: 4
Agent total movement: 7029.0
Agent final location: 128.53045654296875
Using policy model
Running tree world for 16000 steps...
Tree world run complete.
Agent health: -18.404022216796875
Agent fruit eaten: 68
Agent poisonous fruit eaten: 38
Agent total movement: 1532.0
Agent final location: 275.07000732421875
Using baseline model
Running tree world for 17000 steps...
Tree world run complete.
Agent health: -0.030433446168899536
Agent fruit eaten: 235
Agent poisonous fruit eaten: 43
Agent total movement: 11026.0
Agent final location: 237.8943328857422
Using policy model
Running tree world for 18000 steps...
Tree world run complete.
Agent health: -0.04264034330844879
Agent fruit eaten: 11
Agent poisonous fruit eaten: 0
Agent total movement: 5636.0
Agent final location: 454.2172546386719
Using baseline model
Running tree world for 19000 steps...
Tree world run complete.
Agent health: -19.029998779296875
Agent fruit eaten: 21
Agent poisonous fruit eaten: 21
Agent total movement: 2470.0
Agent final location: 249.70462036132812
Using policy model
Running tree world for 20000 steps...
Tree world run complete.
Agent health: -0.024329781532287598
Agent fruit eaten: 86
Agent poisonous fruit eaten: 23
Agent total movement: 9293.0
Agent final location: 306.8660888671875
Using baseline model
Running tree world for 21000 steps...
Tree world run complete.
Agent health: -0.054847344756126404
Agent fruit eaten: 108
Agent poisonous fruit eaten: 0
Agent total movement: 12130.0
Agent final location: 98.52704620361328
Using policy model
Running tree world for 22000 steps...
Tree world run complete.
Agent health: -0.04264046251773834
Agent fruit eaten: 0
Agent poisonous fruit eaten: 0
Agent total movement: 5000.0
Agent final location: 543.0065307617188
Using baseline model
Running tree world for 23000 steps...
Tree world run complete.
Agent health: -0.04721805453300476
Agent fruit eaten: 23
Agent poisonous fruit eaten: 0
Agent total movement: 5621.0
Agent final location: 347.7994079589844
Using policy model
Running tree world for 24000 steps...
Tree world run complete.
Agent health: -0.08336533606052399
Agent fruit eaten: 261
Agent poisonous fruit eaten: 57
Agent total movement: 15284.0
Agent final location: 188.3932342529297
Using baseline model
Running tree world for 25000 steps...
Tree world run complete.
Agent health: -0.04264059662818909
Agent fruit eaten: 52
Agent poisonous fruit eaten: 0
Agent total movement: 9189.0
Agent final location: 362.982666015625
Using policy model
Running tree world for 26000 steps...
Tree world run complete.
Agent health: -0.10092897713184357
Agent fruit eaten: 199
Agent poisonous fruit eaten: 52
Agent total movement: 15292.0
Agent final location: 639.0255126953125
Using baseline model
Running tree world for 27000 steps...
Tree world run complete.
Agent health: -0.008109942078590393
Agent fruit eaten: 60
Agent poisonous fruit eaten: 29
Agent total movement: 1573.0
Agent final location: 153.0112762451172
Using policy model
Running tree world for 28000 steps...
Tree world run complete.
Agent health: -0.04264034330844879
Agent fruit eaten: 0
Agent poisonous fruit eaten: 0
Agent total movement: 5000.0
Agent final location: 250.48973083496094
Using baseline model
Running tree world for 29000 steps...
Tree world run complete.
Agent health: -0.0727308839559555
Agent fruit eaten: 106
Agent poisonous fruit eaten: 15
Agent total movement: 11552.0
Agent final location: 295.6921081542969
Using policy model
Running tree world for 30000 steps...
Tree world run complete.
Agent health: -0.04264034330844879
Agent fruit eaten: 0
Agent poisonous fruit eaten: 0
Agent total movement: 5000.0
Agent final location: 164.8227081298828
Using baseline model
Running tree world for 31000 steps...
Tree world run complete.
Agent health: -0.016670122742652893
Agent fruit eaten: 22
Agent poisonous fruit eaten: 22
Agent total movement: 2250.0
Agent final location: 211.34654235839844
Using policy model
Running tree world for 32000 steps...
Tree world run complete.
Agent health: -18.602920532226562
Agent fruit eaten: 28
Agent poisonous fruit eaten: 28
Agent total movement: 1593.0
Agent final location: 279.26678466796875
Using baseline model
Running tree world for 33000 steps...
Tree world run complete.
Agent health: -4.833704948425293
Agent fruit eaten: 29
Agent poisonous fruit eaten: 18
Agent total movement: 2878.0
Agent final location: 56.93700408935547
Using policy model
Running tree world for 34000 steps...
Tree world run complete.
Agent health: -0.059425026178359985
Agent fruit eaten: 38
Agent poisonous fruit eaten: 0
Agent total movement: 7518.0
Agent final location: 663.5001220703125
Using baseline model
Running tree world for 35000 steps...
Tree world run complete.
Agent health: -0.0640026330947876
Agent fruit eaten: 167
Agent poisonous fruit eaten: 0
Agent total movement: 19097.0
Agent final location: 235.0590057373047
Using policy model
Running tree world for 36000 steps...
Tree world run complete.
Agent health: -16.040494918823242
Agent fruit eaten: 14
Agent poisonous fruit eaten: 14
Agent total movement: 3330.0
Agent final location: 67.19371795654297
Using baseline model
Running tree world for 37000 steps...
Tree world run complete.
Agent health: -0.0925673395395279
Agent fruit eaten: 113
Agent poisonous fruit eaten: 7
Agent total movement: 16458.0
Agent final location: 213.64425659179688
Using policy model
Running tree world for 38000 steps...
Tree world run complete.
Agent health: -0.04264041781425476
Agent fruit eaten: 0
Agent poisonous fruit eaten: 0
Agent total movement: 5000.0
Agent final location: 416.6015930175781
Using baseline model
Running tree world for 39000 steps...
Tree world run complete.
Agent health: -0.047065407037734985
Agent fruit eaten: 6
Agent poisonous fruit eaten: 0
Agent total movement: 5750.0
Agent final location: 189.98170471191406
Using policy model
Running tree world for 40000 steps...
Tree world run complete.
Agent health: -0.056373029947280884
Agent fruit eaten: 9
Agent poisonous fruit eaten: 0
Agent total movement: 6125.0
Agent final location: 229.34231567382812
Using baseline model
Running tree world for 41000 steps...
Tree world run complete.
Agent health: -0.016700729727745056
Agent fruit eaten: 17
Agent poisonous fruit eaten: 17
Agent total movement: 2875.0
Agent final location: 367.41156005859375
Using policy model
Running tree world for 42000 steps...
Tree world run complete.
Agent health: 823.3892211914062
Agent fruit eaten: 487
Agent poisonous fruit eaten: 29
Agent total movement: 42000.0
Agent final location: 169.4147186279297
Using baseline model
Running tree world for 43000 steps...
Tree world run complete.
Agent health: -10.249841690063477
Agent fruit eaten: 17
Agent poisonous fruit eaten: 9
Agent total movement: 4926.0
Agent final location: 193.50570678710938
Using policy model
Running tree world for 44000 steps...
Tree world run complete.
Agent health: -19.822113037109375
Agent fruit eaten: 96
Agent poisonous fruit eaten: 61
Agent total movement: 1849.0
Agent final location: 254.7816925048828
Using baseline model
Running tree world for 45000 steps...
Tree world run complete.
Agent health: -0.012367144227027893
Agent fruit eaten: 22
Agent poisonous fruit eaten: 22
Agent total movement: 2250.0
Agent final location: 472.19512939453125
Using policy model
Running tree world for 46000 steps...
Tree world run complete.
Agent health: -0.6532852053642273
Agent fruit eaten: 153
Agent poisonous fruit eaten: 16
Agent total movement: 13347.0
Agent final location: 212.35494995117188
Using baseline model
Running tree world for 47000 steps...
Tree world run complete.
Agent health: -0.013130053877830505
Agent fruit eaten: 140
Agent poisonous fruit eaten: 42
Agent total movement: 7137.0
Agent final location: 488.4181213378906
Using policy model
Running tree world for 48000 steps...
Tree world run complete.
Agent health: -0.050269871950149536
Agent fruit eaten: 5
Agent poisonous fruit eaten: 0
Agent total movement: 5625.0
Agent final location: 181.16148376464844
Using baseline model
Running tree world for 49000 steps...
Tree world run complete.
Agent health: -0.04264034330844879
Agent fruit eaten: 237
Agent poisonous fruit eaten: 22
Agent total movement: 19109.0
Agent final location: 373.0135803222656
Using policy model
Running tree world for 50000 steps...
Tree world run complete.
Agent health: -0.051795631647109985
Agent fruit eaten: 74
Agent poisonous fruit eaten: 16
Agent total movement: 6821.0
Agent final location: 386.6492004394531
world.agent.model.use_policy = False # <-- this will toggle back to true after the world is reset
run_simulation(world, steps=10000,record=True)Using policy model
Running tree world for 10000 steps...
Tree world run complete.
Agent health: 898.1937866210938
Agent fruit eaten: 160
Agent poisonous fruit eaten: 0
Agent total movement: 10000.0
Agent final location: 352.5928649902344
from tree_world.visualize import visualize_treeworld_run
visualize_treeworld_run(
world.tree_locations.numpy().tolist(),
[tree.name for tree in world.trees],
[tree.is_poisonous for tree in world.trees],
world.record_positions,
world.record_healths,
world.config.max_health,
title="TreeWorld run",
save_path="tree_world_run.png",
show=False,
)/Users/alockett/dev/tree-world/src/tree_world/visualize.py:226: UserWarning: Glyph 108 (l) missing from font(s) Noto Emoji.
fig.savefig(save_path, bbox_inches="tight", dpi=150)
/Users/alockett/dev/tree-world/src/tree_world/visualize.py:226: UserWarning: Glyph 112 (p) missing from font(s) Noto Emoji.
fig.savefig(save_path, bbox_inches="tight", dpi=150)
(<Figure size 800x800 with 2 Axes>, <Axes: title={'center': 'TreeWorld run'}>)/Users/alockett/dev/tree-world/venv/lib/python3.12/site-packages/IPython/core/events.py:82: UserWarning: Glyph 108 (l) missing from font(s) Noto Emoji.
func(*args, **kwargs)
/Users/alockett/dev/tree-world/venv/lib/python3.12/site-packages/IPython/core/events.py:82: UserWarning: Glyph 112 (p) missing from font(s) Noto Emoji.
func(*args, **kwargs)
/Users/alockett/dev/tree-world/venv/lib/python3.12/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 108 (l) missing from font(s) Noto Emoji.
fig.canvas.print_figure(bytes_io, **kw)
/Users/alockett/dev/tree-world/venv/lib/python3.12/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 112 (p) missing from font(s) Noto Emoji.
fig.canvas.print_figure(bytes_io, **kw)
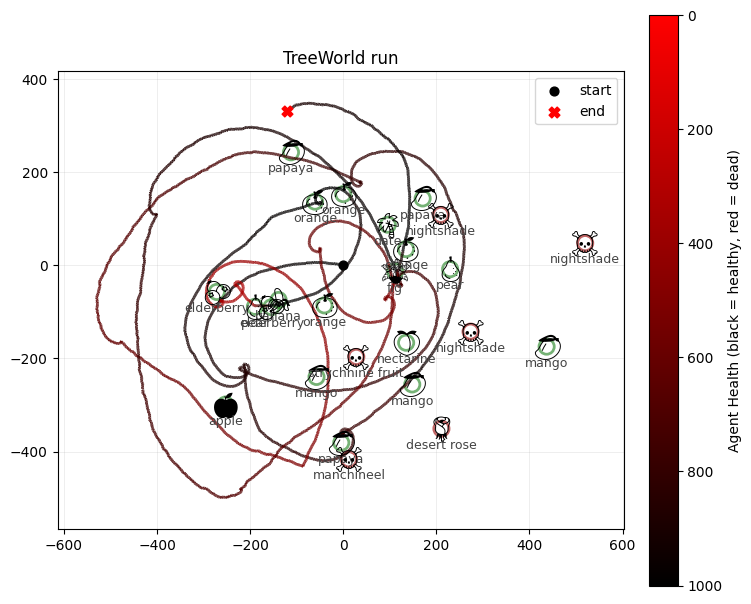
Conclusion¶
Our RL policy has learned to optimize a bit over our baseline policy; in particular, it can exploit rewards a bit better. In a few cases, the RL policy survives indefinitely (10,000+ steps). However, it has a few deficiences:
Our RL policy needs a better baseline, which will take a little work to craft (GAE or PPO)
Our sensors are still too impoverished and could give the agent better information; for instance, neither controller can see poison fruit very well when it is close to edible fruit.
Our RL policy can’t really plan; it is reactive and runs step by step
Given these issues, rather than working more on the RL policy at this time, it would be best to work on the following:
Improve our ability to locate and identify reward states, for instance by learning the drive classifier from sensors + rewards
Work on planning over the memory, perhaps by diffusing a high-reward trajectory to the goal from the memory
Add a local sensor to give better information about the local environment to the controller
With that said, I want to emphasize the following claim:
Using a spatial map, a set of drives, and a goal-driven control framework, the task of building an RL controller has been made far simpler than training a controller just on the sensory inputs
This claim remains to be proven; I may add a general policy gradient controller above to compare the difficulty of learning.