Our goal is to build an agent that can infer space as a consequence of how its actions affect its sensor data. The space that we will infer is a kind of map of what the agent should expect to observe with its sensors in each place. That is, we want a spatial memory that maps locations to expected sensor data. This is our first goal.
In the spirit of the Tolman Eichenbaum Machine of Whittington et al., our agent will learn the space for this spatial memory through a variational autoencoder, that is to say, through a harmonic process that aligns the sensor data that is read from the memory with the locations that are inferred from the senses.
As a consequence, our spatial memory must be invertible; given the current sensor observations, the memory should provide one or more guesses for the correct location. We will model this as a sampling procedure over the memory contents.
Once our memory is invertible, we can use it for other purposes. For instance, if we can classify sensor data according to whether or not it satisfies the agent’s needs (e.g. water or food), then we can search the memory for locations where these needs can be satisfied. Ideally, these locations will be close to the present position of the agent, so we want our search to be conditioned on the agent’s position. We will represent this as taking a conditional sample.
Furthermore, the efficiency of our memory will be determined by its size and the computational cost of querying it, so we will need tools to manage the size.
Thus we have four tasks for our memory:
Store sensory data by location such that this data can be accurately retrieved
Sample potential locations that may correspond to observed sensor data to aid localization
Sample potential nearby locations where needed resources may be obtained
Manage size to optimize computational cost vs. retrieval quality
In this notebook, we’ll develop our memory on these lines and verify that it works. The library code for the memory is in tree_world.models.memory.SpatialMemory, but we’ll show all relevant code as we go.
To simplify our task, we’ll assume that locations are known and correct here. Our locations will be 2-D points within our simulated tree world. In this way, we’ll be able to verify the memory under ideal conditions that should extrapolated to the case of learned space.
For information on the sensors, see the Simulation Design Notebook.
A Memory to Remember Senses by Location¶
The purpose of the memory is to remember what would be sensed in a given location that was visited. In a continuous setting, we will never visit the exact same location twice, so we do not want a memory per se. Instead, we want an interpolator that can predict the expected sensory value well.
Suppose, then that our agent has visited a sequence of locations , observing at each step, yielding a sequence of pairs . Given a new location , we want to estimate provided that for all , . But this is just a regression! Our “memory” is not really a memory; it is a regression model trained from the dataset of visited points.
Our memory, then is a regression function trained on the visited points. However, we need a model that can be rapidly trained, because the memory needs to be immediately available from timestep to timestep. As a first approach, we can simply interpolate with an attention kernel.
In our case, our location estimates are generated by the agent and come with error, which we model as a Gaussian with diagonal covariance matrix (i.e., independent variation in each location dimension). Thus to each we associate a vector of deviations , and we want to regress . We can compute a location affinity kernel between the inputs and based on the -scaled distance as
where logs make the relationships easier to see. Vector division is componentwise, and is just the density function of a Gaussian -- the variance combines the measurement error on both and and represents the variance of .
Next, we can take a softmax over to get a set of affinity weights that will weight our dataset examples according to their closeness to the query point , accounting for measurement error:
From here, we can regress directly on the dataset to obtain the sensor estimate by
which estimates the sensor output as a weighted average of the past sensor values.
import torch
import math
def read_memory(query_location: torch.Tensor, query_deviation: torch.Tensor,
memory_locations: torch.Tensor, memory_deviation: torch.Tensor,
memory_values: torch.Tensor) -> torch.Tensor:
# we expect query_location to be a tensor of shape (..., num_queries, dim) (but num_queries can be 1 or missing)
# we expect query_deviation to be a tensor of shape (..., num_queries, dim) (but num_queries can be 1 or missing)
# we expect memory_locations to be a tensor of shape (..., num_keys, dim)
# we expect memory_deviation to be a tensor of shape (..., num_keys, dim)
# we expect memory_values to be a tensor of shape (..., num_keys, embed_dim)
single_query = query_location.ndim < memory_locations.ndim
if single_query:
query_locations = query_location[..., None, :]
query_deviations = query_deviation[..., None, :]
assert query_locations.ndim == query_deviations.ndim == memory_locations.ndim == memory_deviation.ndim == memory_values.ndim
# compute the combined variance, which has shape (..., num_queries, num_keys)
variance = query_deviation**2 + memory_deviation**2
log_k = (
- 0.5 * ((query_location - memory_locations).pow(2) / variance).sum(dim=-1)
- torch.log(variance).sum(dim=-1)
- 0.5 * math.log(2 * math.pi) * variance.shape[-1]
)
# the location affinity weights have shape (..., num_queries, num_keys)
w = torch.softmax(log_k, dim=-1)
hat_z = torch.bmm(w, memory_values)
if single_query:
hat_z = hat_z.squeeze(-2)
return hat_zNow, you might notice that this kernel looks very similar to dot product attention, and then you might ask whether we could recast it to make use of efficient tools for handling long-context attention, such as flash attention. The answer is that you could, but you would be changing the topology of the location space in so doing, and you would have to work that change all the way through the math. We might do that later. For now, the clarity of keeping our space as is preferable.
Testing Basic Memory Reads¶
We will now check how well a memory that is populated with sensor data can do at building a model of a tree world. For this purpose, we’ll allow our locations to be the “true” positions of our 2-D world space and avoid worrying about the agent learning a location representation for now; if the memory won’t work for the the “truth”, then it won’t work for latent approximations of locations either. Also, we’ll keep it simple by avoiding any compression of the sensor data; we’ll just work with the sensor data in full dimension (which comes from a sentence embedding model here, specifically BAAI/bge-large-en-v1.5)
First we import the relevant elements of our simulation, and initialize a tree world.
from tree_world.simulation import TreeWorld, TreeWorldConfig, SimpleSensor
# create a world and memory
print("Creating world and memory...")
config = TreeWorldConfig()
world = TreeWorld.random_from_config(config)
config.embed_dim = 1024 # we'll use embeddings from text, and
# print out the tree locations
print("--------------------------------")
for tree in world.trees:
print(tree.tree_id, tree.name, tree.location.detach().cpu().numpy().tolist())
print("--------------------------------")
print("Creating sensor...")
sensor = SimpleSensor.from_config(config)
closest_distance, sense_value, closest_tree = sensor.sense(world, torch.zeros(2), None)
print("--------------------------------")
print(f"Testing sensor at (0, 0)")
print(f"Closest tree: {closest_tree.tree_id} ({closest_tree.name}) at {closest_distance.item():.2f}m")
print(f"Sense value: {sense_value}")
print(f"Tree embeddings: {closest_tree.embedding}")
print("--------------------------------")
Creating world and memory...
--------------------------------
Winston pear [-363.0957946777344, -10.466400146484375]
Kramer banana [311.3721923828125, -214.82005310058594]
Peter date [-241.35983276367188, 291.2801208496094]
Rupert papaya [166.30374145507812, -285.3287658691406]
Julia elderberry [338.356689453125, 34.61469650268555]
Homer cherry [33.31411361694336, 290.41046142578125]
Richard strychnine fruit [-424.9556884765625, -314.7217102050781]
Abigail strychnine fruit [252.83644104003906, -77.73773956298828]
Rachel pear [182.71652221679688, -13.932559967041016]
Homer papaya [-23.01750373840332, 1.541074514389038]
Rupert strychnine fruit [-126.63072204589844, -318.89959716796875]
Ursula strychnine fruit [-56.491607666015625, -225.31246948242188]
Kamala orange [168.79798889160156, -29.354480743408203]
Clinton pear [28.278409957885742, -41.138980865478516]
Kamala strychnine fruit [106.21846008300781, 55.16600799560547]
George nightshade [-228.00747680664062, 131.72265625]
Florence mango [-360.0386047363281, 41.14054489135742]
Wendy nightshade [-29.32383155822754, 101.1414794921875]
Sam apple [-387.7786865234375, 49.98896026611328]
Elizabeth manchineel [-136.2073516845703, -71.43858337402344]
Toby cherry [163.6121826171875, -25.735822677612305]
Rachel cherry [378.7822265625, 131.08822631835938]
Winston banana [-110.94941711425781, 199.56362915039062]
Jane manchineel [-143.9712677001953, -337.9956359863281]
Yogi apple [187.3199005126953, 215.32290649414062]
--------------------------------
Creating sensor...
--------------------------------
Testing sensor at (0, 0)
Closest tree: Homer (papaya) at 23.07m
Sense value: tensor([-0.0371, -0.0026, 0.0041, ..., 0.0004, 0.0112, 0.0349])
Tree embeddings: tensor([-0.0085, -0.0285, -0.0133, ..., -0.0257, -0.0131, 0.0169])
--------------------------------
We can see that each tree has a name, a fruit type, and a 2-D coordinate in the world. The tree embeddings is generated under the hood by passing the name and tree type to our sentence embedder (see tree_world.embeddings.embed_text_sentence_transformers for the code).
Further, we have built a sensor and we can see that the embedding of the closest tree to the origin is similar to the value that we read from the sensor at the origin.
Let’s find a way to see what the sensors can “see”
print("Preparing to make a grid of points...")
def make_2D_grid(points_per_axis: int, world_size: float=500.0):
points = torch.linspace(-world_size, world_size, points_per_axis)
return torch.cartesian_prod(points, points)
num_points = 100
print(f"Making a grid of points, {num_points} x {num_points}...")
grid = make_2D_grid(points_per_axis=num_points)
print(f"Made a grid of points: {grid.shape}; running sensor...")
_, sensor_values, _ = sensor.sense(world, grid, None)
print(f"sensor_values.shape: {sensor_values.shape}")Preparing to make a grid of points...
Making a grid of points, 100 x 100...
Made a grid of points: torch.Size([10000, 2]); running sensor...
sensor_values.shape: torch.Size([10000, 1024])
%matplotlib inline# generate a 3D embedding of the sensor values
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
def make_rgb_model_from_sensor_values(values: torch.Tensor):
sensor_np = values.cpu().numpy()
N = sensor_np.shape[0]
k = min(4000, N) # tune subset size
idx = np.random.RandomState(42).choice(N, size=k, replace=False)
pca = PCA(n_components=3)
rgb = pca.fit_transform(sensor_np[idx])
return lambda x: pca.transform(x), rgb.min(axis=0), rgb.max(axis=0)
rgb_model, rgb_min, rgb_max = make_rgb_model_from_sensor_values(sensor_values)def plot_sensor_field(values: torch.Tensor, key="Sensor Field"):
rgb = rgb_model(values.cpu().detach().numpy())
# normalize the colors to be between 0 and 1 for display
rgb = (rgb - rgb_min) / (rgb_max - rgb_min + 1e-8)
rgb = np.clip(rgb, 0, 1)
H = W = int(math.sqrt(values.shape[0]))
img = rgb.reshape(H, W, 3)
fig, ax = plt.subplots(figsize=(6,6))
ax.imshow(
img,
extent=[-500, 500, -500, 500], # [xmin, xmax, ymin, ymax]
origin='lower',
interpolation='nearest',
aspect='equal', # square pixels in world space
)
ax.set_title(f"{key} (PCA colors)")
ax.axis("off")
for tree in world.trees:
x, y = tree.location.cpu().numpy()
color = "red" if tree.is_poisonous else "green"
ax.scatter(
y, x,
c=color, marker="x" if tree.is_poisonous else "o",
s=80, edgecolor="k"
)
return img, fig, axbase_sensor_field, fig, ax = plot_sensor_field(sensor_values)/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/1373293567.py:25: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(
Now, let’s create a memory and provide a way to show its contents.
from tree_world.models.memory import SpatialMemory
memory = SpatialMemory(
location_dim=config.dim,
sensory_dim=config.sensory_embedding_dim,
embed_dim=config.embed_dim, # note that if embed_dim=sensory_dim our memory does NOT compress or project inputs
max_memory_size=1024, # <-- beyond this size we will truncate the oldest memories
)
def plot_memory_field(train_locations: torch.Tensor, plot_locations: torch.Tensor, sd: float=1.0, match_threshold: float=None):
# clear out the memory
memory.reset()
_, sensor_data, _ = sensor.sense(world, train_locations, None)
# now we can call memory.write(locations, location_sds, senses) to write data
train_location_sds = torch.empty_like(train_locations).fill_(sd)
memory.write(train_locations, train_location_sds, sensor_data)
# now we can call memory.read(locations, location_sds) to read data
plot_location_sds = torch.empty_like(plot_locations).fill_(sd)
read_data = memory.read(plot_locations[None, ...], plot_location_sds[None, ...], match_threshold=match_threshold)
# plot the data
plot_sensor_field(read_data.squeeze(0), key="Memory Field")
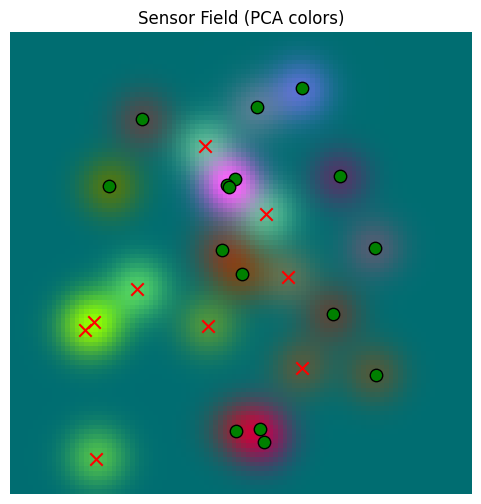
return read_data.squeeze(0)First, let’s see how our memory does at just recalling the same data
train_locations = make_2D_grid(points_per_axis=100)
read_data =plot_memory_field(train_locations, train_locations)/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/1373293567.py:25: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(
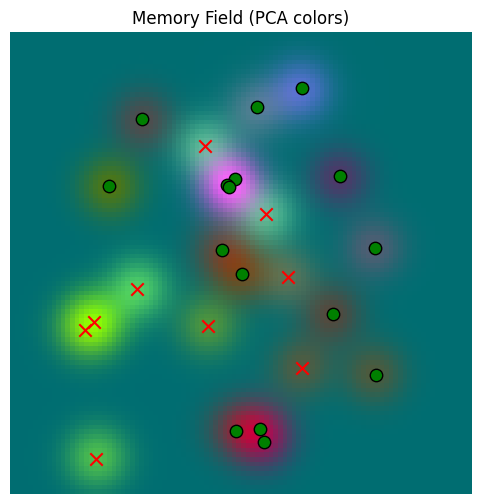
We can see here that the memory and the sensor yield plots appear virtually the same, so the memory is reading well. Just to be sure, we can compare them directly:
error = torch.norm(sensor_values - read_data, dim=-1)
print(f"Min Error: {error.min().item():.6f}")
print(f"Mean Error: {error.mean().item():.6f}")
print(f"Max Error: {error.max().item():.6f}")
print(f"Std Dev on Error: {error.std().item():.6f}")
Min Error: 0.000000
Mean Error: 0.000000
Max Error: 0.000000
Std Dev on Error: 0.000000
So the memory can read and write well. Now let’s give it less data. Let’s start with a smaller grid.
train_locations = make_2D_grid(points_per_axis=10)
plot_locations = make_2D_grid(points_per_axis=100)
smaller_grid_read_data = plot_memory_field(train_locations, plot_locations)/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/1373293567.py:25: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(

Our memory now provides a coarser approximation, as we expect. What if we provide random points, centered at the origin?
train_locations = torch.randn(100,2) * 100
plot_locations = make_2D_grid(points_per_axis=100)
gaussian_read_data = plot_memory_field(train_locations, plot_locations)/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/1373293567.py:25: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(

So the memory read quality is a good approximation near the origin, where it has more observations, but worse further away. This is all as we would expect.
But still, do we really want to let points where we don’t have good data be estimated from something far away? That doesn’t make sense. That’s why we snuck in the match_threshold parameter above, which lets us throw out approximants where there are no close points. You can look at SpatialMemory.get_location_affinity() for details, but basically we alter the read kernel to set if for the match threshold .
gaussian_read_data_thresholded = plot_memory_field(train_locations, plot_locations, match_threshold=100.0)/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/1373293567.py:25: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(

Much better now; we only make sensor estimates for values that are close.
Classifying the Memory According to Drives¶
We are learning a location model that can predict senses from actions based on a memory. However, we also want to use that memory to search for where our agent can find fruit to satisfy its hunger.
But to search the memory for things that satisfy hunger, we need to characterize sensory inputs in terms of the drives that they satisfy. So, we will build a drive embedding classifier that takes classifies inputs across an array of mutually exclusive drives or motivations by computing
which we train on the tree embeddings.
from tree_world.models.drives import train_drive_classifier
# we only want to train on the tree names (e.g. mango, pear, etc.), not the ids (Bob, Alice, etc.)
drive_classifier, drive_keys = train_drive_classifier(config, with_ids=False)
inverse_drive_keys = {v: k for k, v in drive_keys.items()}
print("--------------------------------")
tree_classifications = drive_classifier(torch.stack([tree.embedding for tree in world.trees]))
for tree, classification in zip(world.trees, tree_classifications):
drive_idx = classification.argmax().item()
drive = inverse_drive_keys[drive_idx]
print(f"{tree.tree_id} -- {tree.name} -> {drive} ({classification[drive_idx].item()*100:.2f}%)")
Drive Embedding Classifier Loss (with fruit amount): 0.30583107471466064 MSE: 1.1801565960922744e-05 Accuracy: 100.00%
--------------------------------
Winston -- pear -> edible (100.00%)
Kramer -- banana -> edible (99.99%)
Peter -- date -> edible (99.99%)
Rupert -- papaya -> edible (99.93%)
Julia -- elderberry -> edible (100.00%)
Homer -- cherry -> edible (100.00%)
Richard -- strychnine fruit -> poison (93.02%)
Abigail -- strychnine fruit -> poison (63.39%)
Rachel -- pear -> edible (100.00%)
Homer -- papaya -> edible (100.00%)
Rupert -- strychnine fruit -> poison (98.77%)
Ursula -- strychnine fruit -> poison (84.75%)
Kamala -- orange -> edible (99.99%)
Clinton -- pear -> edible (100.00%)
Kamala -- strychnine fruit -> poison (93.49%)
George -- nightshade -> poison (71.96%)
Florence -- mango -> edible (100.00%)
Wendy -- nightshade -> poison (67.50%)
Sam -- apple -> edible (100.00%)
Elizabeth -- manchineel -> edible (89.43%)
Toby -- cherry -> edible (99.98%)
Rachel -- cherry -> edible (99.99%)
Winston -- banana -> edible (100.00%)
Jane -- manchineel -> poison (84.54%)
Yogi -- apple -> edible (99.98%)
So our drive classifer correctly identifies the edible fruit.
Now let’s visualize our sensor space in terms of drive satisfaction.
def plot_drive_field(values: torch.Tensor, key="Drives from Sensors", temperature=1.0):
drive_by_location = drive_classifier(values)
if temperature != 1.0:
drive_by_location = drive_by_location ** (1.0 / temperature)
drive_by_location = drive_by_location / drive_by_location.sum(dim=-1, keepdim=True)
# we'll use a color scheme of red for poisonous, green for edible, and blue for unknown
color_map = torch.tensor([[1, 0, 0], [0, 1, 0], [0, 0, 1]], dtype=drive_by_location.dtype)
color_by_location = torch.mm(drive_by_location, color_map).detach()
H = W = int(math.sqrt(color_by_location.shape[0]))
img = color_by_location.reshape(H, W, 3)
fig, ax = plt.subplots(figsize=(6,6))
ax.imshow(
img,
extent=[-500, 500, -500, 500], # [xmin, xmax, ymin, ymax]
origin='lower',
interpolation='nearest',
aspect='equal', # square pixels in world space
)
ax.set_title(f"{key} (Red=Poison, Green=Food, Blue=Neutral)")
ax.axis("off")
for tree in world.trees:
x, y = tree.location.cpu().numpy()
color = "red" if tree.is_poisonous else "green"
ax.scatter(
y, x,
c=color, marker="x" if tree.is_poisonous else "o",
s=80, edgecolor="k"
)
return img, fig
drive_field, fig = plot_drive_field(sensor_values)
/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/2340518492.py:29: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(

We see that the sensors yield predictions of edible only around the trees, as expected, with poisonous food detected wherever there are not too many non-poisonous trees close by.
Now let’s see what happens if we use our memory. We’ll use the memory made from Gaussian reads near the origin.
mem_drive_field, fig = plot_drive_field(gaussian_read_data, key="Drives from Memory")/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/2340518492.py:29: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(

Hmm, our memory is a little overactive. Maybe it’s because of the way we chose to read based on the closest locations, even if they were far away in reality. To fix this, we should use the match_threshold parameter from above.
_, _ = plot_drive_field(gaussian_read_data_thresholded, key="Drives from Memory at threshold=25")
/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/2340518492.py:29: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(

But this is still not really informative ... maybe it would be better to have a more peaked visualization to better observe the differences here.
_, _ = plot_drive_field(gaussian_read_data_thresholded, key="Drives from Memory at threshold=25, temperature=10", temperature=10)/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/2340518492.py:29: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(

Now that we have a view of the memory based on drives, we can use it to find locations where there may be fruit.
Searching the Memory for Information¶
We intend to use the memory three different ways:
To read the expected sensory value of a location (as above)
To verify an estimated location based on the sensory value (for learning the [Tolman Eichenbaum Machine] VAE)
To find desirable sensory locations based on a goal (to satisfy the agent’s needs)
The first usage can be modeled as a regression over prior observations, as we did above. The second usage can ALSO be realized as a regression IF the sensor results are sufficiently distinctive. That is, so long as distinct locations () lead to distinct observations (), then we could apply the same regression-based read as before with the values swapped ().
The second usage can be subsumed into the third, where we interpret the “goal” as being the current sensory observation.
The third usage requires something different from the first; in general, the basic drives of the organism will not be unique. So each non-poisonous fruit tree will satisfy hunger, and hence we no longer want a strict function (one input -> one output). Instead, we want to search the memory to provide multiple possible matches for a query value.
Since our memory does not contain exact values for us to retrieve in any case, it will suffice to think of this search as a sampling problem. That is, we want to use our observation dataset to learn a distribution that we can flexibly sample to get locations likely to satisfy our goal.
Now, to specify what “meeting our goal” is. Let us suppose we have a scoring function for sensor observations that assigns large positive values to matches, zero to ambiguous possible matches, and large negative numbers to irrelevant or mismatched data.
So we want a conditional probability distribution over such that
Which is to say that our samples are well aligned with our search key.
Now, for the simplest case, we can suppose there is a search key , which will be a vector in the same space as our sensory output , so that we can define the affinity of to via dot products . This gives us a straightforward way to compute the affinity of previously observed locations to our search; we just need to figure out .
Because we already built a drive classifier for our sensors, we can use this classifier to get our affinity. For hunger, we can choose the sensor from the definition of the classifier above, which is determined by a search key . Let’s print it out.
y_hunger = drive_classifier.drive_embeddings.weight[drive_keys["edible"]].data
print(f"y_hunger = {y_hunger}")
value_of_apple =(world.tree_name_embeddings["apple"] * y_hunger).pow(2).sum().item()
print(f"value of apple for hunger = {value_of_apple} >> 0")
y_hunger = tensor([ 0.9604, -1.3328, -1.8091, ..., -2.5060, -1.4005, 1.5127])
value of apple for hunger = 1.2691352367401123 >> 0
So, we can find the edible fruit by sampling over our memory using as a search key.
But what does sampling in this case mean? And how can we sample efficiently?
As a first approach, it is fairly simple to sample using a Gaussian mixture model (GMM). A GMM is just weighted sum of Gaussians:
where is just the Gaussian kernel and the weights are a softmax over the alignment scores,
To sample from this mixture, we first sample from as a multinomial, and then we use the resulting as the centroid of Gaussian with covariance .
def sample_conditional_gmm(memory_locations: torch.Tensor, memory_location_sds: torch.Tensor, memory_values: torch.Tensor,
search_key: torch.Tensor, sigma_scale: float=25.0, num_samples: int=1, temperature: float=None):
# memory_locations has shape (..., num_observations, dim)
# memory_values has shape (..., num_observations, embed_dim)
# search_key has shape (..., embed_dim)
if temperature is None:
temperature = memory_values.shape[-1]**(0.5)
# compute the alignment scores
s_t = torch.bmm(memory_values, search_key[..., None]).squeeze(-1)
w_t = torch.softmax(s_t / temperature, dim=-1)
# sample from the mixture, result will be (..., num_samples)
t = torch.multinomial(w_t, num_samples=num_samples, replacement=True)
t = t.unsqueeze(-1).repeat(1, 1, memory_locations.shape[-1])
loc_mean = memory_locations.gather(dim=-2, index=t)
loc_sd = memory_location_sds.gather(dim=-2, index=t)
return loc_mean + torch.randn_like(loc_mean) * sigma_scale * loc_sd
# take a sample
hunger_sample = sample_conditional_gmm(
memory.memory_locations, memory.memory_location_sds, memory.memory_senses, y_hunger[None, ...], num_samples=250,
temperature=1.0
).squeeze(0)
hunger_sample_deviation = torch.norm(hunger_sample - hunger_sample.mean(dim=-1, keepdim=True), dim=-1).std()
print(f"Got a sample of shape {hunger_sample.shape} with deviation {hunger_sample_deviation}")
_, sensor_data_at_samples, _ = sensor.sense(world, hunger_sample, None)
drives_at_samples = drive_classifier(sensor_data_at_samples)
avg_hunger_at_samples = drives_at_samples[:, drive_keys["edible"]].mean().item()
min_hunger_at_samples = drives_at_samples[:, drive_keys["edible"]].min().item()
print(f"Average hunger at samples: {avg_hunger_at_samples}")
print(f"Minimum hunger at samples: {min_hunger_at_samples}")
Got a sample of shape torch.Size([250, 2]) with deviation 53.28778076171875
Average hunger at samples: 0.9949816465377808
Minimum hunger at samples: 0.4727088510990143
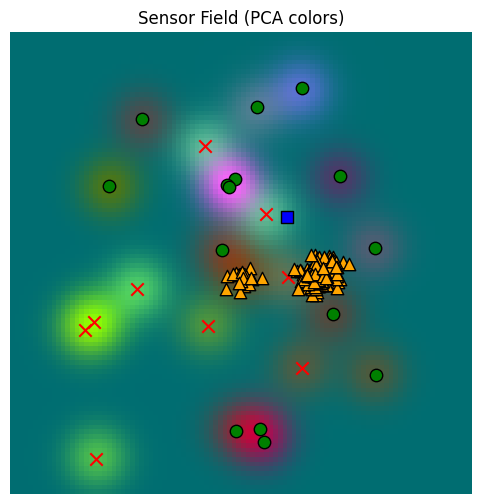
So we get a sample that has a high match with the hunger drive, as expected. But it looks like our samples are clustered too tightly! Where are our samples?
_, fig, ax = plot_sensor_field(sensor_values)
for sample in hunger_sample:
ax.scatter(sample[0], sample[1], c="orange", marker="^", s=80, edgecolor="k")/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/1373293567.py:25: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(
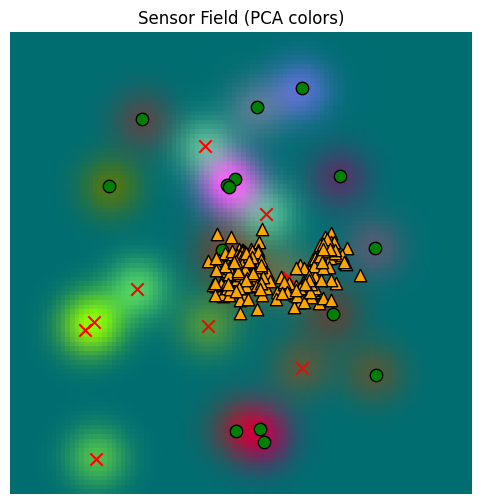
Well, these samples are ok, but they aren’t really representative enough. We need to raise the temperature of our softmax. Here, I’ve set the default for temperature to be , matching the kernel typically used for dot product attention. Let’s use that instead of temperature=1.
# take a sample
hunger_sample_temperature = sample_conditional_gmm(
memory.memory_locations, memory.memory_location_sds, memory.memory_senses, y_hunger[None, ...], num_samples=250,
sigma_scale=1.0,
temperature=None # <-- default; uses sqrt(d)
).squeeze(0)
hunger_sample_deviation = torch.norm(hunger_sample_temperature - hunger_sample_temperature.mean(dim=-1, keepdim=True), dim=-1).std()
print(f"Got a sample of shape {hunger_sample_temperature.shape} with deviation {hunger_sample_deviation}")
_, sensor_data_at_samples_temperature, _ = sensor.sense(world, hunger_sample_temperature, None)
drives_at_samples_temperature = drive_classifier(sensor_data_at_samples_temperature)
avg_hunger_at_samples_temperature = drives_at_samples_temperature[:, drive_keys["edible"]].mean().item()
min_hunger_at_samples_temperature = drives_at_samples_temperature[:, drive_keys["edible"]].min().item()
print(f"Average hunger at samples: {avg_hunger_at_samples_temperature}")
print(f"Minimum hunger at samples: {min_hunger_at_samples_temperature}")Got a sample of shape torch.Size([250, 2]) with deviation 70.107177734375
Average hunger at samples: 0.7755414843559265
Minimum hunger at samples: 0.12780991196632385
_, fig, ax = plot_sensor_field(sensor_values)
for sample in hunger_sample_temperature:
ax.scatter(sample[0], sample[1], c="orange", marker="^", s=80, edgecolor="k")/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/1373293567.py:25: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(
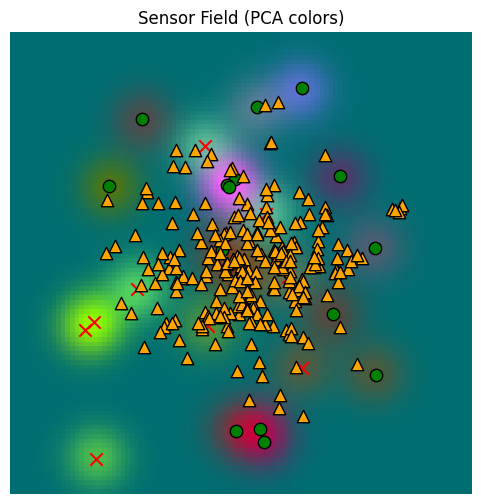
It’s less heavily clustered now, but it’s also less focused. Recall that the memory was populated from a Gaussian set of original locations, explaining why the samples are clustered about the origin and don’t reach the edges of the space.
Note that our minimum hunger value has dropped significantly, though. We get more diverse samples, but they may have lower quality overall.
Yet we need to go further. For our agent, we don’t just want to find a match for our drive anywhere; we want to preference matches that are close to the agent’s current position.
We’ll accomplish this by adjusting to take a given location into account:
def sample_conditional_gmm_with_location(
memory_locations: torch.Tensor, memory_location_sds: torch.Tensor, memory_values: torch.Tensor,
search_key: torch.Tensor, search_location: torch.Tensor, search_location_sd: torch.Tensor,
sigma_scale: float=1.0, num_samples: int=1, temperature: float=None, location_weight: float=0.01
):
# memory_locations has shape (..., num_observations, dim)
# memory_values has shape (..., num_observations, embed_dim)
# search_key has shape (..., embed_dim)
if temperature is None:
temperature = memory_values.shape[-1]**(0.5)
# compute the alignment scores
s_t = torch.bmm(memory_values, search_key[..., None]).squeeze(-1)
# compute the combined variance, which has shape (..., num_queries, num_keys)
variance = search_location_sd**2 + memory_location_sds**2
log_k = (
- 0.5 * ((search_location - memory_locations).pow(2) / variance).sum(dim=-1)
- 0.5 * torch.log(variance).sum(dim=-1)
- 0.5 * math.log(2 * math.pi) * variance.shape[-1]
)
w_t = torch.softmax((s_t + location_weight * log_k) / temperature, dim=-1)
# sample from the mixture, result will be (..., num_samples)
t = torch.multinomial(w_t, num_samples=num_samples, replacement=True)
t = t.unsqueeze(-1).repeat(1, 1, memory_locations.shape[-1])
loc_mean = memory_locations.gather(dim=-2, index=t)
loc_sd = memory_location_sds.gather(dim=-2, index=t)
return loc_mean + torch.randn_like(loc_mean) * sigma_scale * loc_sd
# take a sample
location = torch.tensor([[100.0, 100.0]])
location_sd = torch.tensor([[25.0, 25.0]])
hunger_sample_with_location = sample_conditional_gmm_with_location(
memory.memory_locations, memory.memory_location_sds, memory.memory_senses, y_hunger[None, ...], location, location_sd,
num_samples=250, sigma_scale=1.0, temperature=1.0
).squeeze(0)
hunger_sample_deviation_with_location = torch.norm(hunger_sample_with_location - hunger_sample_with_location.mean(dim=-1, keepdim=True), dim=-1).std()
print(f"Got a sample of shape {hunger_sample_with_location.shape} with deviation {hunger_sample_deviation_with_location}")
_, sensor_data_at_samples_with_location, _ = sensor.sense(world, hunger_sample_with_location, None)
drives_at_samples_with_location = drive_classifier(sensor_data_at_samples_with_location)
avg_hunger_at_samples_with_location = drives_at_samples_with_location[:, drive_keys["edible"]].mean().item()
min_hunger_at_samples_with_location = drives_at_samples_with_location[:, drive_keys["edible"]].min().item()
print(f"Average hunger at samples: {avg_hunger_at_samples_with_location}")
print(f"Minimum hunger at samples: {min_hunger_at_samples_with_location}")Got a sample of shape torch.Size([250, 2]) with deviation 32.35943603515625
Average hunger at samples: 0.9999754428863525
Minimum hunger at samples: 0.9981056451797485
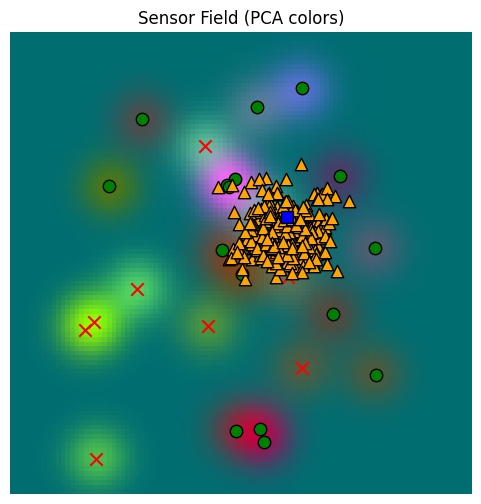
Here we’ve biased the search to locations just up and to the right of the origin (marked with a blue square below). When this is done, we get a set of samples (yellow triangles) that is noticeably different from the free sampling above.
Unlike when we were reading the memory above, we do NOT want to restrict match locations (match_locations above) when we are trying to find candidates to resolve drives. If we did that, we would exclude all faraway locations, and the only satisfaction might actually be far away. So we want to allow the memory search farther afield, if needed.
_, fig, ax = plot_sensor_field(sensor_values)
for sample in hunger_sample_with_location:
ax.scatter(sample[0], sample[1], c="orange", marker="^", s=80, edgecolor="k")
ax.scatter(location[0, 0], location[0, 1], c="blue", marker="s", s=80, edgecolor="k")/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/1373293567.py:25: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(
This last sample function is also implemented, with a few more bells and whistles, on the memory object:
sample_hunger_from_memory = memory.sample(
location, location_sd, y_hunger[None, ...], num_samples=250, sigma_scale=1.0, temperature=1.0,
match_threshold=None, location_temperature=100.0
).squeeze( )
hunger_sample_from_memory_deviation = torch.norm(sample_hunger_from_memory - sample_hunger_from_memory.mean(dim=-1, keepdim=True), dim=-1).std()
print(f"Got a sample of shape {sample_hunger_from_memory.shape} with deviation {hunger_sample_from_memory_deviation}")
_, sensor_data_at_samples_from_memory, _ = sensor.sense(world, sample_hunger_from_memory, None)
drives_at_samples_from_memory = drive_classifier(sensor_data_at_samples_from_memory)
avg_hunger_at_samples_from_memory = drives_at_samples_from_memory[:, drive_keys["edible"]].mean().item()
min_hunger_at_samples_from_memory = drives_at_samples_from_memory[:, drive_keys["edible"]].min().item()
print(f"Average hunger at samples: {avg_hunger_at_samples_from_memory}")
print(f"Minimum hunger at samples: {min_hunger_at_samples_from_memory}")
Got a sample of shape torch.Size([250, 2]) with deviation 31.077287673950195
Average hunger at samples: 0.6531907916069031
Minimum hunger at samples: 0.11184682697057724
_, fig, ax = plot_sensor_field(sensor_values)
for sample in sample_hunger_from_memory:
ax.scatter(sample[0], sample[1], c="orange", marker="^", s=80, edgecolor="k")
ax.scatter(location[0, 0], location[0, 1], c="blue", marker="s", s=80, edgecolor="k")/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/1373293567.py:25: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(
Pruning the memory¶
If we insert observation tuples every time step, our memory will fill up very quickly.
Let be the total number of entries into memory. Practically speaking, with current hardware we can easily read and search up to without any specialized hardware, and with a good GPU we can get to if we only need a few frames per second. With some optimization, we could extend that up towards with flash attention, and with low-dimensional vectors we can potentially go even higher. But just because we could doesn’t mean we should. If a robot operates at 10 cycles per second (roughly the speed of the human cortex alpha waves), then a memory with would be exhausted in 410 seconds -- less than 7 minutes. Not much of a memory.
Given that the goal is to model , remembering everything is computationally wasteful as well, since many of the observation points are close together and overlap. So it makes sense to optimize a little bit. Here are some options:
Update instead of insert at write time, if points are close enough together.
Learn a simple regressor for periodically and discard the old memory entirely
Periodically prune the memory and/or reposition observation points
Updating at write time is feasible, but interrupts the main behavioral cycle. SpatialMemory has an update parameter that does exactly this, but it’s not a systematic way to manage the memory, and probably is not the best option.
Learning another regressor would do well for reading, and for small datasets of a few thousand or tens of thousands of points, it can be done in parallel to the behavioral loop. But a model for sampling would need to be learned as well. Furthermore, if we run this regression at time and it finishes at time , then we have to remember the observations that happen during . It could be complicated to integrate the two, unless the new regressor is just a new sequence of observation points with the same read and sample behavior as above.
Which brings us to the final option, either pruning or reconfiguring the observation points periodically. This can be done in parallel to running a policy that depends on the memory: the policy would simple access the memory as usual from time until the update is ready at time . Then it would remove the observations up to time , replacing them with the reduced set, but keeping the observations between and .
Formally, let be the observations between times and , not including . The pruning / reconfiguration process generates a new set of virtual observations
where and indicates the memory read function applied to memory contents . Then, when is ready at time , the observation set used by the agent is hot-swapped from to , preserving all new observations.
To begin to prune, we can estimate the importance of each observation by reading from the memory with that observation removed. This can be done by computing and masking the diagonal before reading.
def read_one_removed(memory_locations: torch.Tensor, memory_deviation: torch.Tensor,
memory_values: torch.Tensor, match_threshold: float=None) -> torch.Tensor:
# we expect memory_locations to be a tensor of shape (..., num_keys, dim)
# we expect memory_deviation to be a tensor of shape (..., num_keys, dim)
# we expect memory_values to be a tensor of shape (..., num_keys, embed_dim)
memory_loc_q = memory_locations[..., None, :, :]
memory_loc_k = memory_locations[..., None, :]
memory_loc_sd_q = memory_deviation[..., None, :, :]
memory_loc_sd_k = memory_deviation[..., None, :]
# compute the combined variance, which has shape (..., num_queries, num_keys)
variance = memory_loc_sd_q**2 + memory_loc_sd_k**2
location_delta = memory_loc_q - memory_loc_k
log_k = (
- 0.5 * (location_delta.pow(2) / variance).sum(dim=-1)
- torch.log(variance).sum(dim=-1)
- 0.5 * math.log(2 * math.pi) * variance.shape[-1]
)
# make a mask to zero out the diagonal
diag_mask = torch.eye(log_k.shape[-2], device=log_k.device, dtype=torch.bool)
while diag_mask.ndim < log_k.ndim:
diag_mask = diag_mask[None, ...]
# zero out the diagonal
log_k = log_k.masked_fill(diag_mask, -float('inf'))
if match_threshold is not None:
threshold_check = torch.norm(location_delta, dim=-1) > match_threshold
log_k = log_k.masked_fill(threshold_check, float('-inf'))
# the location affinity weights have shape (..., num_queries, num_keys)
w = torch.softmax(log_k, dim=-1)
# we have to account for the case where there are no nearby matches
inactive = (log_k <= float('-inf')).all(dim=-1)
w = torch.where(inactive[..., None], torch.zeros_like(log_k), w)
hat_z = torch.bmm(w, memory_values)
error = torch.norm(hat_z - memory_values, dim=-1)
dependencies = w > (1 / memory_values.shape[-2])
return hat_z, error, dependencies
# let's fill up our memory with random locations, more than before
memory.reset()
locations = torch.randn(1, 1024, 2) * 100
location_sds = torch.full_like(locations, 10.0)
_, sensory, _ = sensor.sense(world, locations.squeeze(0), None)
print(f"Writing {locations.shape} observations to memory")
memory.write(locations, location_sds, sensory[None, ...])
z_leave_one_out, error_leave_one_out, dependencies_leave_one_out = read_one_removed(
memory.memory_locations, memory.memory_location_sds, memory.memory_senses, match_threshold=25.0
)
print(f"Memory size: {memory.memory_locations.shape[1]}")
print()
print(f"Min error of leave-one-out read: {error_leave_one_out.min().item()}")
print(f"Mean error of leave-one-out read: {error_leave_one_out.mean().item()}")
print(f"Max error of leave-one-out read: {error_leave_one_out.max().item()}")
print(f"Std dev of leave-one-out error: {error_leave_one_out.std().item()}")
dependencies_per_slot = dependencies_leave_one_out.float().sum(dim=-1).squeeze()
print()
print(f"Min dependencies per slot: {dependencies_per_slot.min().item()}")
print(f"Mean dependencies per slot: {dependencies_per_slot.mean().item()}")
print(f"Max dependencies per slot: {dependencies_per_slot.max().item()}")
print(f"Std dev of dependencies per slot: {dependencies_per_slot.std().item()}")
Writing torch.Size([1, 1024, 2]) observations to memory
Memory size: 1024
Min error of leave-one-out read: 0.0016184506239369512
Mean error of leave-one-out read: 0.12764671444892883
Max error of leave-one-out read: 4.752317905426025
Std dev of leave-one-out error: 0.2841464579105377
Min dependencies per slot: 0.0
Mean dependencies per slot: 16.591796875
Max dependencies per slot: 45.0
Std dev of dependencies per slot: 10.440792083740234
So, there are items whose removal is ignorable (the min error, typically < 0.01), and other items that are isolated (min dependencies=0) and cannot be removed.
We can start by removing the non-isolated items with the lowest error. When doing so, we want to be careful not to remove two items that were depending on each other; then we might have worse error than projected.
Let’s see how many we can prune that way.
def generate_prune_candidates(
error_leave_one_out: torch.Tensor, dependencies_leave_one_out: torch.Tensor, max_error_to_prune: float=0.05
):
# remove candidates that are a dependency of another candidate with a lower error
sorted_error, error_indices = torch.sort(error_leave_one_out, dim=-1)
unsort_indices = torch.argsort(error_indices, dim=-1)
dependencies = dependencies_leave_one_out.gather(
dim=-2, index=error_indices[..., None].repeat(1, 1, dependencies_leave_one_out.shape[-1])
).gather(
dim=-1, index=error_indices[..., None, :].repeat(1, dependencies_leave_one_out.shape[-1], 1)
)
# generate a list of all candidates, ignoring dependencies
candidates = sorted_error < max_error_to_prune
# remove candidates with zero dependencies
num_dependencies = dependencies.long().sum(dim=-1)
candidates = candidates & (num_dependencies > 0)
# remove candidates that are a dependency of another candidate with a lower error
dependencies_mask = torch.tril(dependencies, diagonal=-1).any(dim=-1)
candidates = candidates & dependencies_mask
return candidates.gather(dim=-1, index=unsort_indices)
prune_candidates_005 = generate_prune_candidates(error_leave_one_out, dependencies_leave_one_out, max_error_to_prune=0.05)
prune_candidates_005 = prune_candidates_005.squeeze().nonzero()
print()
print("Prune candidates at 0.05: ", prune_candidates_005.cpu().numpy().tolist())
print("Number of items to prune at 0.05: ", prune_candidates_005.shape[0])
prune_candidates_001 = generate_prune_candidates(error_leave_one_out, dependencies_leave_one_out, max_error_to_prune=0.01)
prune_candidates_001 = prune_candidates_001.squeeze().nonzero()
print()
print("Prune candidates at 0.01: ", prune_candidates_001.cpu().numpy().tolist())
print("Number of items to prune at 0.01: ", prune_candidates_001.shape[0])
Prune candidates at 0.05: [[4], [5], [9], [11], [13], [14], [16], [30], [31], [37], [38], [40], [55], [58], [59], [63], [70], [72], [75], [82], [83], [92], [95], [98], [100], [101], [108], [111], [114], [120], [121], [123], [124], [130], [140], [155], [157], [158], [160], [166], [170], [172], [181], [182], [184], [185], [196], [199], [201], [203], [212], [214], [216], [223], [235], [236], [237], [238], [244], [245], [246], [249], [252], [257], [260], [261], [267], [268], [273], [280], [290], [298], [302], [303], [304], [307], [311], [313], [316], [319], [320], [322], [325], [328], [330], [336], [340], [345], [346], [348], [355], [359], [362], [366], [369], [371], [382], [383], [386], [387], [388], [391], [393], [397], [401], [402], [405], [408], [412], [413], [416], [424], [425], [435], [444], [446], [447], [452], [454], [459], [462], [464], [468], [469], [471], [472], [473], [479], [489], [491], [492], [493], [499], [503], [505], [519], [525], [528], [533], [535], [540], [544], [554], [557], [560], [566], [571], [572], [578], [582], [585], [588], [592], [602], [607], [611], [618], [619], [621], [622], [627], [633], [640], [654], [662], [666], [669], [676], [681], [685], [689], [693], [694], [697], [699], [703], [705], [706], [712], [715], [726], [727], [730], [736], [741], [742], [743], [748], [749], [750], [751], [759], [765], [775], [777], [778], [779], [781], [782], [784], [785], [787], [795], [796], [803], [805], [810], [815], [818], [821], [822], [826], [829], [830], [832], [834], [835], [836], [838], [841], [843], [849], [852], [853], [854], [857], [860], [862], [868], [870], [871], [884], [886], [892], [893], [898], [899], [905], [906], [918], [923], [924], [925], [930], [937], [943], [946], [949], [951], [953], [956], [958], [959], [960], [963], [966], [967], [968], [971], [976], [978], [982], [990], [992], [993], [998], [1003], [1004], [1007], [1008], [1009], [1019], [1023]]
Number of items to prune at 0.05: 273
Prune candidates at 0.01: [[83], [273], [525], [528], [578], [854], [862]]
Number of items to prune at 0.01: 7
So then, there are 5-15 items out of 1024 that we safely prune with an error threshold of 0.01, and if we are willing to allow higher error, there are a few hundred.
Further, we can apply this recursively until none are removed. Let’s do the pruning.
starting_memory_locations = memory.memory_locations.clone()
starting_memory_location_sds = memory.memory_location_sds.clone()
starting_memory_senses = memory.memory_senses.clone()
starting_memory_result = memory.read(plot_locations[None, ...], torch.full_like(plot_locations[None, ...], 10.0), match_threshold=25.0)
def prune_memory(memory_locations: torch.Tensor, memory_location_sds: torch.Tensor, memory_senses: torch.Tensor,
max_error_to_prune: float=0.05, match_threshold: float=25.0):
_, error_leave_one_out, dependencies_leave_one_out = read_one_removed(
memory_locations, memory_location_sds, memory_senses, match_threshold=match_threshold
)
prune_candidates = generate_prune_candidates(error_leave_one_out, dependencies_leave_one_out, max_error_to_prune)
# decide what to prune
mem_size = prune_candidates.shape[-1]
prune_size = mem_size -prune_candidates.long().sum(dim=-1).max().item()
scores = mem_size - prune_candidates.float() * torch.arange(prune_candidates.shape[-1], device=prune_candidates.device)[None, ...]
_, pruned_indices = torch.topk(scores, k=prune_size, dim=-1)
pruned_indices_loc = pruned_indices[..., None].repeat(1, 1, memory_locations.shape[-1])
pruned_indices_sense = pruned_indices[..., None].repeat(1, 1, memory_senses.shape[-1])
pruned_memory_locations = memory_locations.gather(dim=-2, index=pruned_indices_loc)
pruned_memory_location_sds = memory_location_sds.gather(dim=-2, index=pruned_indices_loc)
pruned_memory_senses = memory_senses.gather(dim=-2, index=pruned_indices_sense)
num_pruned = prune_candidates.sum(dim=-1)
return num_pruned, pruned_memory_locations, pruned_memory_location_sds, pruned_memory_senses
def recursive_prune_memory(memory_locations: torch.Tensor, memory_location_sds: torch.Tensor, memory_senses: torch.Tensor,
max_error_to_prune: float=0.05, match_threshold: float=25.0, max_prune_steps: int=10):
for _ in range(max_prune_steps):
num_pruned, memory_locations, memory_location_sds, memory_senses = prune_memory(memory_locations, memory_location_sds, memory_senses, max_error_to_prune, match_threshold)
print(f"Pruned removed items: {num_pruned.detach().cpu().numpy().tolist()}")
if num_pruned.max().item() == 0:
break
return memory_locations, memory_location_sds, memory_senses
pruned_memory_locations, pruned_memory_location_sds, pruned_memory_senses = recursive_prune_memory(
starting_memory_locations, starting_memory_location_sds, starting_memory_senses,
max_error_to_prune=0.05, match_threshold=25.0, max_prune_steps=10
)
memory.memory_locations = pruned_memory_locations
memory.memory_location_sds = pruned_memory_location_sds
memory.memory_senses = pruned_memory_senses
print(f"Final memory size: {pruned_memory_locations.shape[1]}")
pruned_memory_result = memory.read(plot_locations[None, ...], torch.full_like(plot_locations[None, ...], 10.0), match_threshold=25.0)
Pruned removed items: [273]
Pruned removed items: [127]
Pruned removed items: [75]
Pruned removed items: [28]
Pruned removed items: [6]
Pruned removed items: [6]
Pruned removed items: [0]
Final memory size: 509
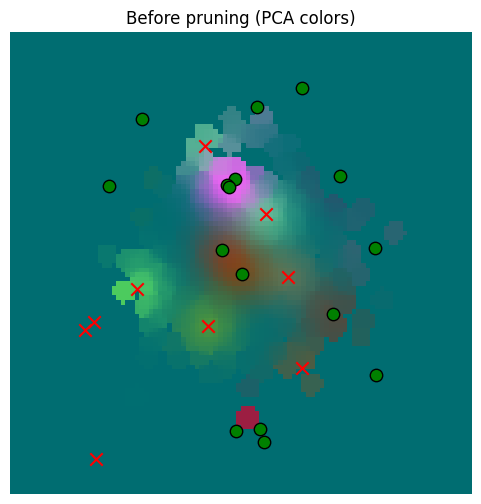
So we’ve pruned our memory almost in half. But now how bad is our error? Let’s compare to sensor data and to the prior data
_ = plot_sensor_field(starting_memory_result.squeeze(0), key="Before pruning")
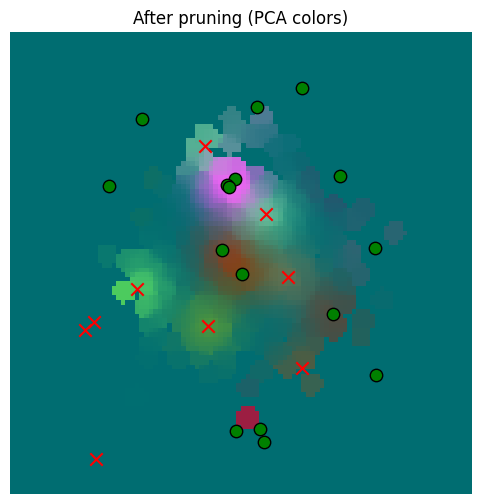
_ = plot_sensor_field(pruned_memory_result.squeeze(0), key="After pruning")
/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/1373293567.py:25: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(
/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/1373293567.py:25: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(
It’s hard to see a difference, but surely there must be one, right? Let’s check the numbers and plot the diff.
error_after_pruning = torch.norm(pruned_memory_result - starting_memory_result, dim=-1)
print(f"Min error (vs. memory read prior) after pruning: {error_after_pruning.min().item()}")
print(f"Mean error (vs. memory read prior) after pruning: {error_after_pruning.mean().item()}")
print(f"Max error (vs. memory read prior) after pruning: {error_after_pruning.max().item()}")
print(f"Std dev of error (vs. memory read prior) after pruning: {error_after_pruning.std().item()}")
error_vs_sensor_prior = torch.norm(starting_memory_result - sensor_values[None, ...], dim=-1)
print()
print(f"Min error (vs. sensor) prior: {error_vs_sensor_prior.min().item()}")
print(f"Mean error (vs. sensor) prior: {error_vs_sensor_prior.mean().item()}")
print(f"Max error (vs. sensor) prior: {error_vs_sensor_prior.max().item()}")
print(f"Std dev of error (vs. sensor) prior: {error_vs_sensor_prior.std().item()}")
error_vs_sensor_after_pruning = torch.norm(pruned_memory_result - sensor_values[None, ...], dim=-1)
print()
print(f"Min error (vs. sensor) after pruning: {error_vs_sensor_after_pruning.min().item()}")
print(f"Mean error (vs. sensor) after pruning: {error_vs_sensor_after_pruning.mean().item()}")
print(f"Max error (vs. sensor) after pruning: {error_vs_sensor_after_pruning.max().item()}")
print(f"Std dev of error (vs. sensor) after pruning: {error_vs_sensor_after_pruning.std().item()}")
Min error (vs. memory read prior) after pruning: 0.0
Mean error (vs. memory read prior) after pruning: 0.010287650860846043
Max error (vs. memory read prior) after pruning: 0.6817408204078674
Std dev of error (vs. memory read prior) after pruning: 0.04173653572797775
Min error (vs. sensor) prior: 2.1720796209291453e-15
Mean error (vs. sensor) prior: 0.4647279381752014
Max error (vs. sensor) prior: 6.12962007522583
Std dev of error (vs. sensor) prior: 0.8044621348381042
Min error (vs. sensor) after pruning: 2.1720796209291453e-15
Mean error (vs. sensor) after pruning: 0.4682459533214569
Max error (vs. sensor) after pruning: 6.12962007522583
Std dev of error (vs. sensor) after pruning: 0.8031671643257141
So in some cases there is significant error, but the distribution of errors vs. the underlying sensor data is basically unaffected.
Let’s plot the diff.
_ = plot_sensor_field((pruned_memory_result - starting_memory_result).squeeze(0), key="Error after pruning (mem read before vs after)")
_ = plot_sensor_field((sensor_values[None, ...] - pruned_memory_result).squeeze(0), key="Error vs. sensor after pruning")
_ = plot_sensor_field((sensor_values[None, ...] - starting_memory_result).squeeze(0), key="Error vs. sensor before pruning")
/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/1373293567.py:25: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(
/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/1373293567.py:25: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(
/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/1373293567.py:25: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(

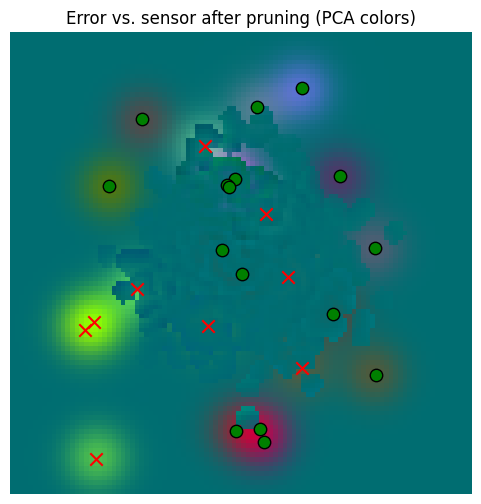
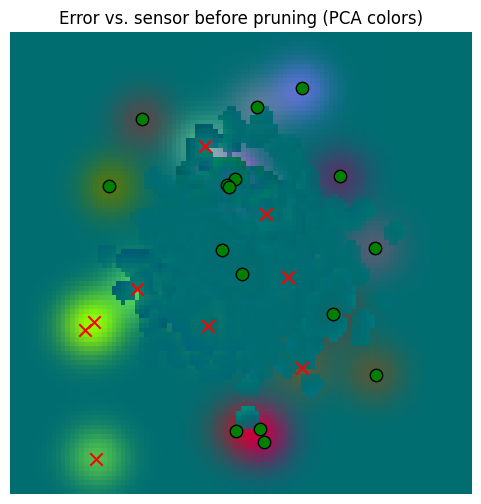
So yes, there’s error, but that error is dwarfed by the error against the sensory data. So our aggressive pruning was probably beneficial.
But we can also regress on the prior memory values to move around the prune values a bit, which should help with this error.
class MemoryRegressor(torch.nn.Module):
def __init__(self, memory: SpatialMemory, memory_locations: torch.Tensor, memory_location_sds: torch.Tensor,
memory_senses: torch.Tensor):
super().__init__()
self.memory = memory
self.memory_locations = torch.nn.Parameter(memory_locations)
self.memory_location_sds = torch.nn.Parameter(memory_location_sds)
self.memory_senses = torch.nn.Parameter(memory_senses)
def forward(self, locations: torch.Tensor, location_sds: torch.Tensor):
self.memory.memory_locations = self.memory_locations
self.memory.memory_location_sds = self.memory_location_sds
self.memory.memory_senses = self.memory_senses
return self.memory.read(locations, location_sds, match_threshold=25.0, detach_senses=False, detach_locations=False)
regressor = MemoryRegressor(memory, pruned_memory_locations, pruned_memory_location_sds, pruned_memory_senses)
optimizer = torch.optim.Adam(regressor.parameters(), lr=0.001)
steps = 100
for i in range(steps):
optimizer.zero_grad()
pruned_memory_result = regressor(plot_locations[None, ...], torch.full_like(plot_locations[None, ...], 10.0))
error = torch.norm(pruned_memory_result - starting_memory_result, dim=-1).pow(2).mean()
if i % 10 == 0:
print(f"Step {i} error: {error.item()}")
error.backward()
optimizer.step()
memory.memory_locations = regressor.memory_locations
memory.memory_location_sds = regressor.memory_location_sds
memory.memory_senses = regressor.memory_senses
pruned_memory_result_regressed = memory.read(
plot_locations[None, ...], torch.full_like(plot_locations[None, ...], 10.0), match_threshold=25.0
)
error_after_pruning = torch.norm(pruned_memory_result_regressed - starting_memory_result, dim=-1)
print(f"Min error (vs. memory read prior) after pruning: {error_after_pruning.min().item()}")
print(f"Mean error (vs. memory read prior) after pruning: {error_after_pruning.mean().item()}")
print(f"Max error (vs. memory read prior) after pruning: {error_after_pruning.max().item()}")
print(f"Std dev of error (vs. memory read prior) after pruning: {error_after_pruning.std().item()}")
error_vs_sensor_prior = torch.norm(starting_memory_result - sensor_values[None, ...], dim=-1)
print()
print(f"Min error (vs. sensor) prior: {error_vs_sensor_prior.min().item()}")
print(f"Mean error (vs. sensor) prior: {error_vs_sensor_prior.mean().item()}")
print(f"Max error (vs. sensor) prior: {error_vs_sensor_prior.max().item()}")
print(f"Std dev of error (vs. sensor) prior: {error_vs_sensor_prior.std().item()}")
error_vs_sensor_after_pruning = torch.norm(pruned_memory_result_regressed - sensor_values[None, ...], dim=-1)
print()
print(f"Min error (vs. sensor) after pruning: {error_vs_sensor_after_pruning.min().item()}")
print(f"Mean error (vs. sensor) after pruning: {error_vs_sensor_after_pruning.mean().item()}")
print(f"Max error (vs. sensor) after pruning: {error_vs_sensor_after_pruning.max().item()}")
print(f"Std dev of error (vs. sensor) after pruning: {error_vs_sensor_after_pruning.std().item()}")Step 0 error: 0.0018476002151146531
Step 10 error: 0.0009380565606988966
Step 20 error: 0.000766694953199476
Step 30 error: 0.0006861960282549262
Step 40 error: 0.000640565063804388
Step 50 error: 0.0006383216823451221
Step 60 error: 0.0006177577306516469
Step 70 error: 0.0006020850269123912
Step 80 error: 0.0005893675261177123
Step 90 error: 0.0005786488763988018
Min error (vs. memory read prior) after pruning: 0.0
Mean error (vs. memory read prior) after pruning: 0.005942051764577627
Max error (vs. memory read prior) after pruning: 0.517316460609436
Std dev of error (vs. memory read prior) after pruning: 0.02310255914926529
Min error (vs. sensor) prior: 2.1720796209291453e-15
Mean error (vs. sensor) prior: 0.4647279381752014
Max error (vs. sensor) prior: 6.12962007522583
Std dev of error (vs. sensor) prior: 0.8044621348381042
Min error (vs. sensor) after pruning: 2.1720796209291453e-15
Mean error (vs. sensor) after pruning: 0.46631109714508057
Max error (vs. sensor) after pruning: 6.12962007522583
Std dev of error (vs. sensor) after pruning: 0.8038018941879272
_ = plot_sensor_field((pruned_memory_result - starting_memory_result).squeeze(0), key="Error after pruning")
_ = plot_sensor_field((pruned_memory_result_regressed - starting_memory_result).squeeze(0), key="Error after pruning + regression")
_ = plot_sensor_field((sensor_values[None, ...] - pruned_memory_result_regressed).squeeze(0), key="Error vs. sensor after pruning + regression")/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/1373293567.py:25: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(
/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/1373293567.py:25: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(
/var/folders/gw/zsqsy8v12h1fsqw6ph5ndprc0000gn/T/ipykernel_83753/1373293567.py:25: UserWarning: You passed a edgecolor/edgecolors ('k') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
ax.scatter(
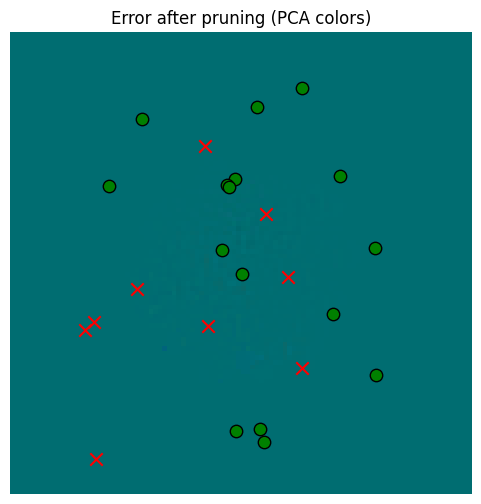

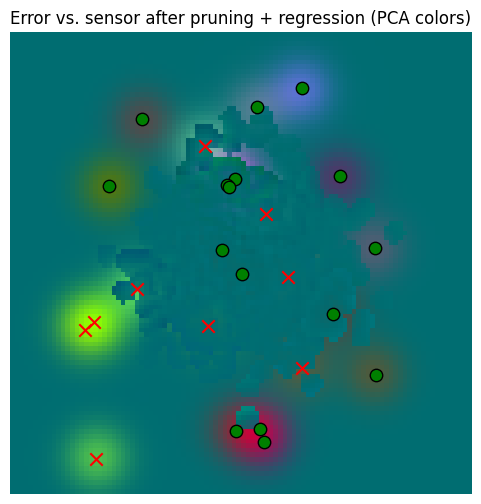
So in the end, regressing gives us a little extra, but in the context of memory read error vs. the sensors, it’s probably not worth it. Pruning alone, however, is very valuable for computational reasons.
SpatialMemory implements prune() but does not regress at present.
memory = SpatialMemory(
max_memory_size=1024,
location_dim=config.dim,
sensory_dim=config.sensory_embedding_dim,
embed_dim=config.embed_dim,
)
locations = torch.randn(1, 1024, 2) * 100
location_sds = torch.full_like(locations, 10.0)
_, sensory, _ = sensor.sense(world, locations.squeeze(0), None)
print(f"Writing {locations.shape} observations to memory")
memory.write(locations, location_sds, sensory[None, ...])
print(f"Before pruning, memory has {memory.memory_locations.shape[1]} items")
memory.prune(max_error_to_prune=0.05, match_threshold=25.0, max_prune_steps=10)
print(f"After pruning, memory has {memory.memory_locations.shape[1]} items")
Writing torch.Size([1, 1024, 2]) observations to memory
Before pruning, memory has 1024 items
After pruning, memory has 558 items
Conclusion¶
That wraps it up for the memory; we can
Insert sensory data by location and retrieve results across the location space
Read locations based on a sensory input and a location guess
Sample locations that potentially can satisfy a drive
Prune the memory to reduce memory and computation
Now we will use these capabilities to build an agent that learns latent locations spaces while seeking to satisfy drives!